오라클 데이터베이스 구조
개발부서와 협업을 하다 보면 데이터베이스에 대한 질문을 종종 하시곤 합니다.
질문에 대해서 조금이나마 도움이 되고자 우리가 사용하는 데이터베이스의 아키텍처에 대해서 알아보도록 하겠습니다.
데이터베이스는 무엇?
모두 아시다시피 사전적 의미로는 '자료 파일을 조직적으로 통합하여 자료 항목의 중복을 없애고 자료를 구조화하여 기억시켜 놓는 자료의 집합체'입니다.
조금 쉽게 비유하자면 우리가 사용하는 엑셀을 떠올릴 수 있을 것 같습니다.
테이블을 엑셀 내의 하나의 시트라고 생각하고 스키마(유저)는 하나의 엑셀 파일이 됩니다. 데이터베이스는 이 엑셀을 모두 저장하고 있는 디렉터리가 되는 것이죠.
즉, 데이터베이스는 데이터를 효율적, 효과적으로 사용하기 위한 엔터프라이즈 엑셀(?)이라고 생각하시면 될 것 같습니다.
오라클 데이터베이스는 어떻게 생겼지?
그렇다면 오라클 데이터베이스는 어떤 구조로 되어있을까요?
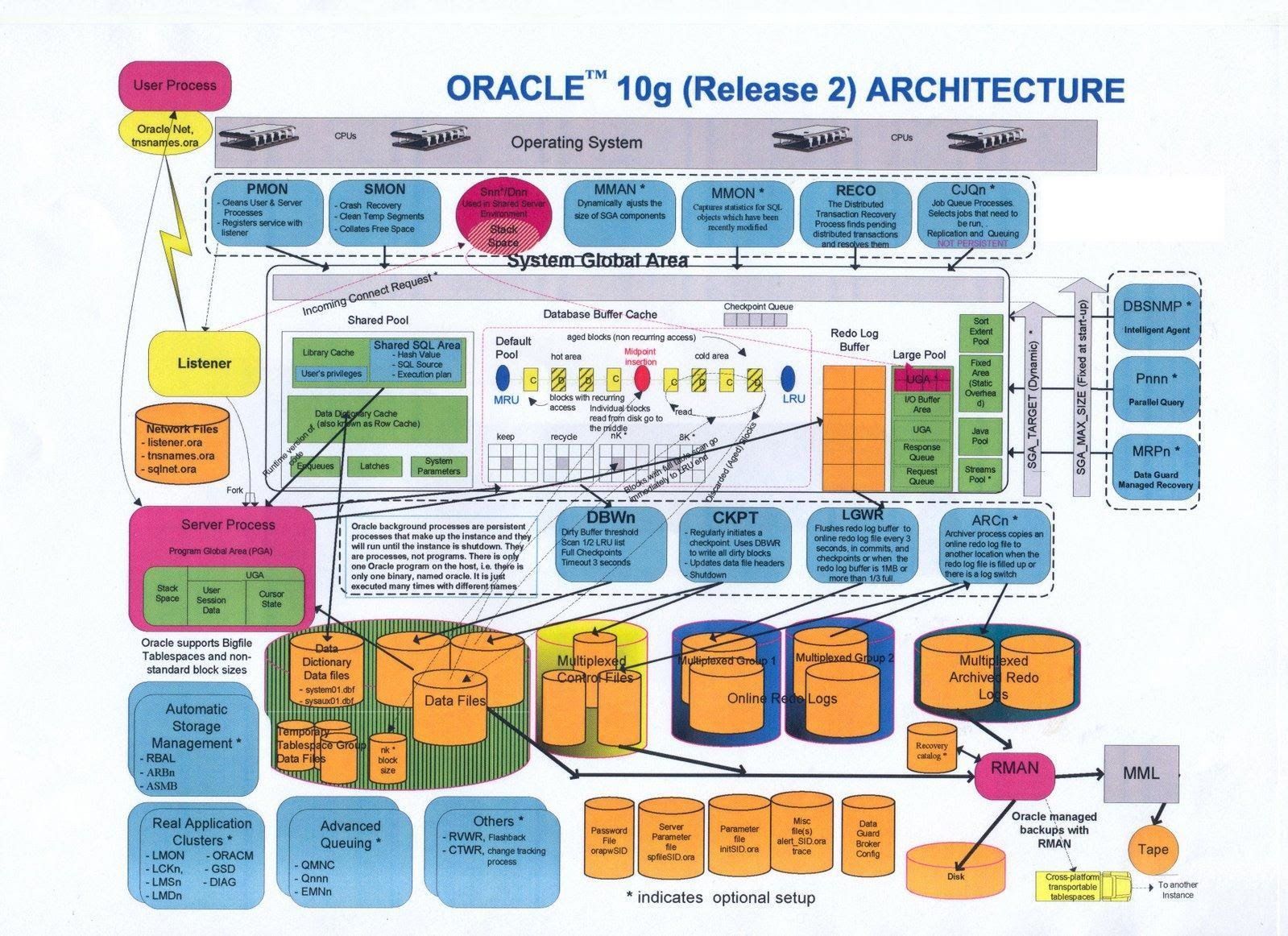
오라클 10g R2 버전의 구조입니다. 복잡합니다.
한 번에 보면 어려우니, 구조를 하나하나 들여다보겠습니다.
오라클 데이터베이스는 크게 두 부분으로 나눌 수 있습니다.
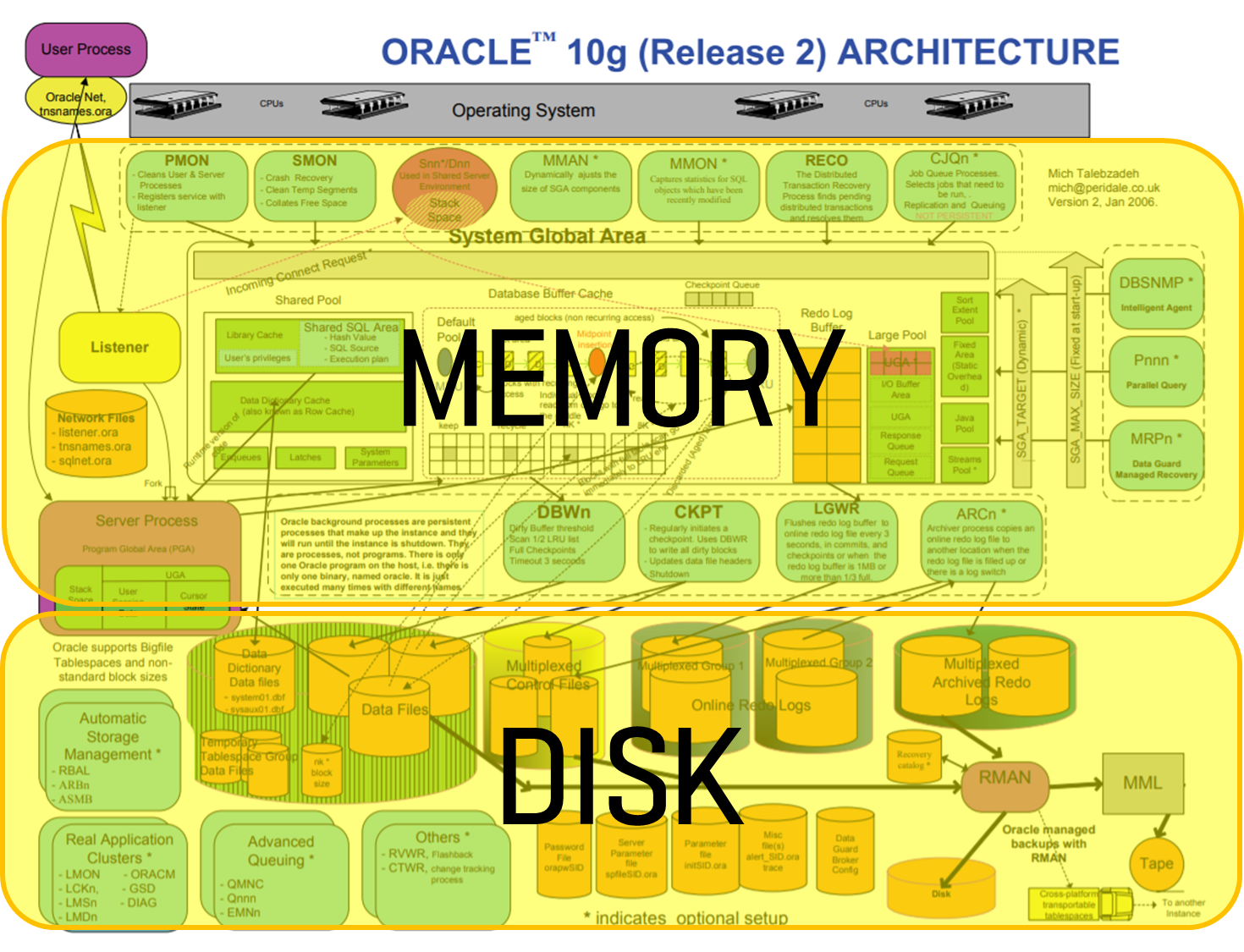
- 메모리
- 디스크
메모리에는 오라클 프로세스와 데이터베이스 엔진이 위치합니다.
디스크에는 실제로 데이터가 저장되는 데이터 파일이 위치합니다.
메모리부터 하나하나 알아가도록 하겠습니다.
메모리에는 SGA(System Global Area)와 백그라운드 프로세스가 위치합니다.
먼저 SGA(System Global Area)를 함께 보겠습니다.
메모리 - SGA(System Global Area)
SGA(System Global Area)는 '여러 사용자와 연결된, 여러 서버 프로세스가 공유하여 사용하는 공간'입니다. 그리고 SGA는 아래와 같은 공간들로 구성되어 있습니다.
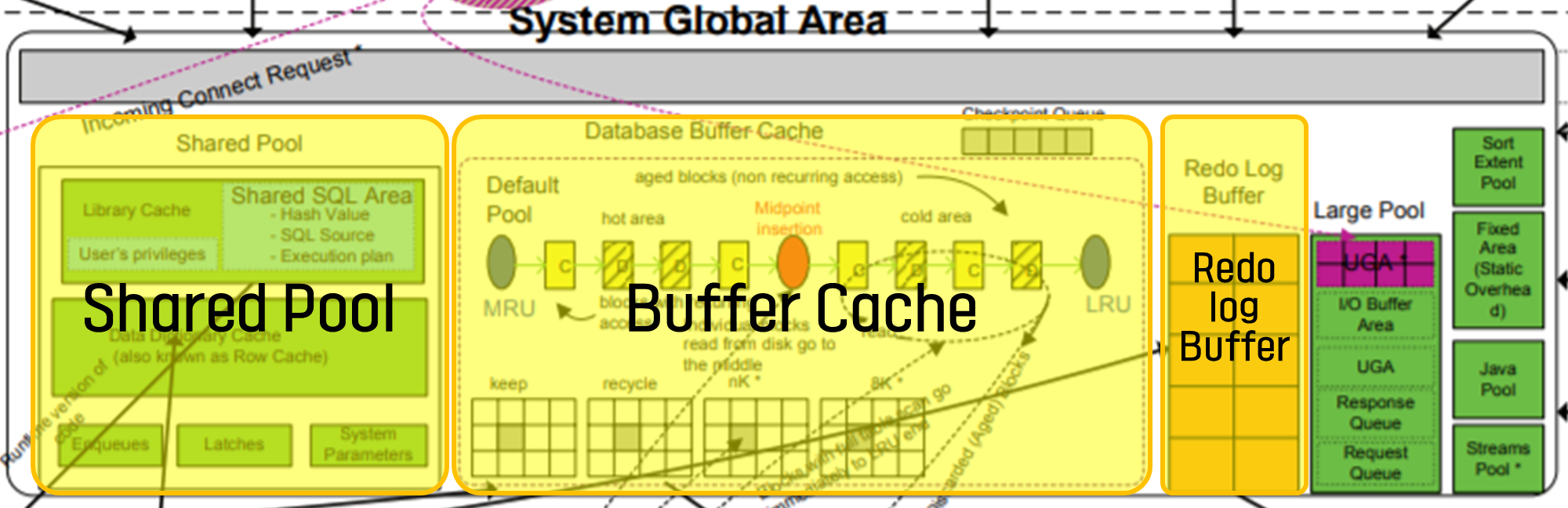
- Shared Pool
- Library Cache
* SQL Area
- Dictionary Cache(Row Cache) - Buffer Cache
- Redo Log Buffer
- 그 외(Large Pool, Java Pool, Stream Pool 등..)
Shared Pool에는 Library Cache와 Dictionary Cache가 있습니다.
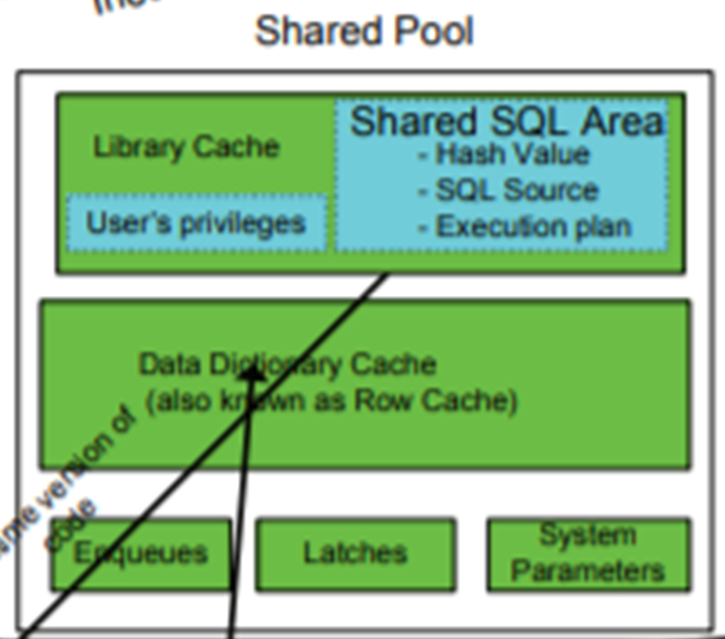
Library Cache는 사용자들이 실행하는 SQL의 실행계획과 SQL ID의 Hash Value 등을 저장합니다. SQL을 처음 실행했을 때와 그 이후 실행했을 때 속도가 약간 빨라짐을 느끼는데, 그 이유 중 하나가 Shared Pool의 Library Cache 때문입니다. 이미 실행되었던 SQL의 실행계획을 저장하여 재활용하기 때문입니다.
Dictionary Cache는 데이터베이스의 메타 데이터를 저장합니다. 데이터베이스 구조에 해당하는 데이터를 메모리에 저장하기 때문에 테이블 변경/조회나 데이터베이스 구조에 대한 변경/조회 할 때 빠른 처리를 할 수 있습니다.
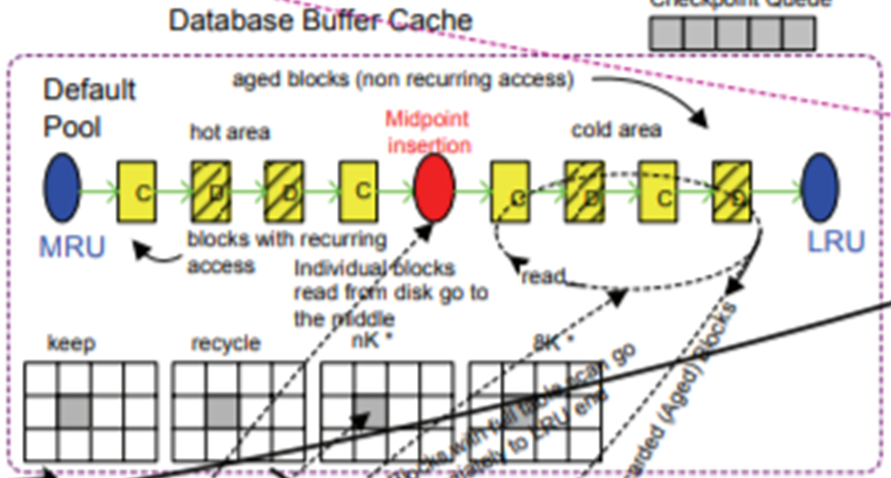
Buffer Cache는 서버 프로세스가 요청받은 SQL에 대한 작업을 수행하는 공간입니다. 데이터베이스 변경이 일어나면 일차적으로 Buffer Cache에서 참조되는 오브젝트를 찾습니다. 참조되는 오브젝트가 있다면 Buffer Cache에서 블록을 변경하고 없다면 디스크에서 Buffer Cache로 오브젝트를 불러와 해당 블록을 변경합니다.
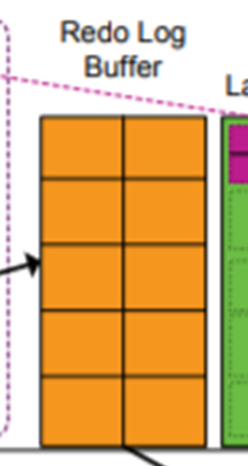
Redo Log Buffer는 데이터를 복구하기 위해 사용되는 공간입니다. SQL을 Redo Entry 형태로 저장하고, 특정 조건이 충족되었을 때 Redo Log Buffer의 내용을 그대로 Redo Log File에 기록합니다. 그리고 DISK의 데이터파일에서 한 번 더 말씀드리겠지만, Redo Log File이 아카이브 파일로 저장되며 데이터베이스 복구에 아주 중요한 역할을 하게 됩니다. Redo Log의 Redo는 RE-DO의 의미로 '다시 적용하다.'라는 의미입니다. 이렇게 외우면 나중에 잊지 않겠죠?
메모리 - 백그라운드 프로세스
오라클의 프로세스는 사용하는 기능에 따라서 여러 가지 프로세스가 있습니다. 그중 필수 프로세스라 불리는 6개의 프로세스와 추가로 아카이브 프로세스에 대해서 알아보겠습니다.
우리가 알아볼 프로세스의 이름과 역할은 아래와 같습니다.
- PMON
- 사용자의 세션이 비정상 종료되었을 때 서버 프로세스가 처리 중이던 데이터를 롤백시키고 프로세스를 정리합니다.
- 다른 프로세스들의 정상 동작 유무를 감시하고 정지된 프로세스를 재기동합니다. - SMON
- 데이터베이스 기동 시 복구가 필요하면 복구 작업을 수행하며, 정기적으로 인스턴스 상태를 감시합니다.
- 더 이상 사용하지 않는 임시 블록 세그먼트들을 재사용 할 수 있게 합니다.
- 데이터 파일의 빈 공간을 연결하여 하나의 큰 공간으로 만듭니다. - RECO
- 데이터베이스 복구 시에 RECO 프로세스에 의해서 복구됩니다. - DBWR
- 특정 조건에 의하여 버퍼 캐시에 있는 수정된(Dirty) 버퍼의 내용을 데이터 파일에 기록합니다. - LGWR
- 특정 조건에 의하여 리두 로그 버퍼의 내용을 리두 로그 파일에 기록하는 역할을 합니다. - CKPT
- 모든 변경된 데이터베이스 버퍼를 디스크 내의 데이터 파일로 저장합니다. 실질적인 순행은 DBWR 프로세스가 수행합니다.
- 체크포인트가 발생하면 데이터 파일과 컨트롤 파일의 헤더를 갱신합니다. - ARC
- 리두 로그 파일을 아카이브 로그 파일로 저장합니다. 명령어 또는 리두 로그 파일이 찼을 때 아카이브 로그 파일을 생성합니다.
디스크
디스크에는 데이터베이스의 메타 데이터를 저장하는 컨트롤 파일과 실질적인 정보를 저장하는 데이터 파일, 그리고 이런 데이터베이스의 안정성을 높여주는 온라인 리두 로그 파일이 있습니다. 그 외에도 여러 가지 파일들이 있지만 이번 시간에는 데이터베이스 구성에 있어 중요한 파일들에 대해서 알아보겠습니다.
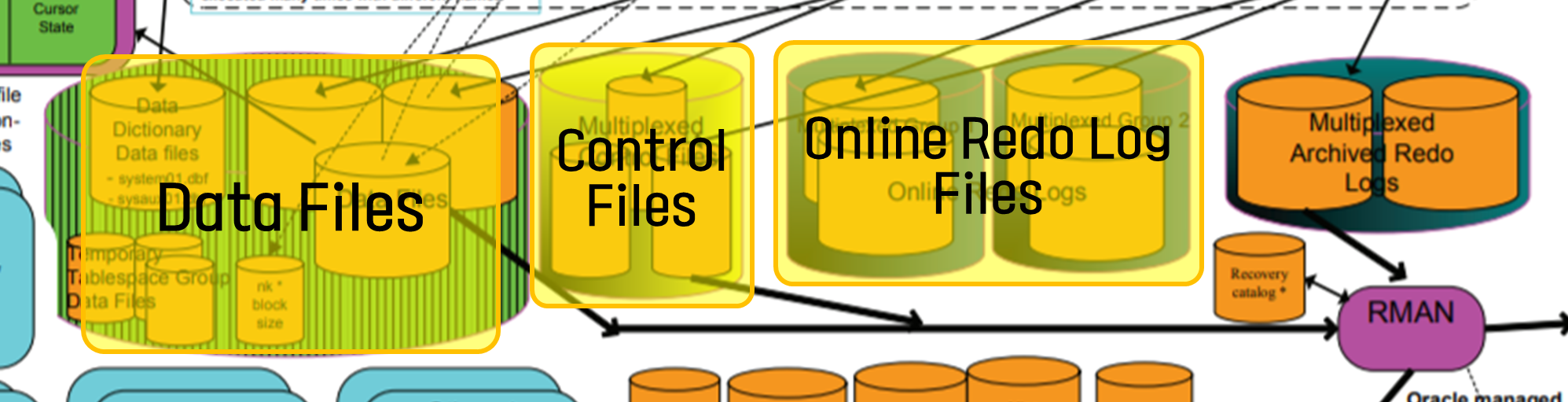
먼저 컨트롤 파일부터 알아보겠습니다.
컨트롤 파일은 데이터베이스의 구조를 바이너리 형식으로 저장하고 있는 파일입니다. 모든 데이터 파일과 온라인 리두 로그 파일 등 위치와 테이블스페이스의 이름, 데이터베이스 시점에 대한 정보들이 기록되어 있습니다. 컨트롤 파일은 데이터베이스의 중요한 정보들이 저장되어 있어 이중화, 삼중화하여 구성합니다.
데이터 파일은 실질적인 데이터가 쌓이는 곳입니다. 데이터 파일에는 데이터베이스 메타 데이터를 저장하는 시스템 테이블스페이스와 그 외 데이터를 저장하는 일반 테이블스페이스로 구분 할 수 있습니다. 시스템 테이블스페이스에는 모든 데이터의 메타 데이터, 즉, 패키지, 트리거, 프로시저, 테이블 정보, 사용자 정보 등이 저장됩니다. 일반 테이블스페이스는 롤백 세그먼트, 임시 세그먼트 등이 있습니다. 그리고 사용자가 사용하기 위한 테이블스페이스도 포함됩니다.
온라인 리두 로그 파일은 데이터베이스 내의 모든 변화를 기록하는 파일입니다. 인스턴스 실패 시 데이터 파일에 쓰이지 않은 커밋된 데이터를 리두 로그 파일을 읽어 복구합니다. 리두 로그 파일은 이처럼 중요한 역할을 하므로 여러 그룹으로, 그리고 하나의 그룹에 두 개 이상의 멤버로 구성합니다.
마치며
오라클 데이터베이스에 대해서 간단하게 알아봤습니다.
한 번에 이해하기는 어렵지만 앞으로 데이터베이스에 관련된 구성이나 기술들을 하나하나 접하다 보면 지금 본 내용이 분명 도움이 되실거라 생각합니다.
앞으로 데이터베이스에 관련된 내용들은 계속 다룰 예정입니다. 오늘 작성한 내용이 모든 기술들의 기본이 되는 내용입니다. 다른 글을 작성하면서 위의 내용에 대해서 꾸준히 다룰 예정이니 지금은 한 번 읽는 정도로 보셔도 좋을 것 같습니다.